Generate Traditional, Combination, Syndromic, or WISCA Antibiograms
Source:R/antibiogram.R
antibiogram.RdCreate detailed antibiograms with options for traditional, combination, syndromic, and Bayesian WISCA methods.
Adhering to previously described approaches (see Source) and especially the Bayesian WISCA model (Weighted-Incidence Syndromic Combination Antibiogram) by Bielicki et al., these functions provides flexible output formats including plots and tables, ideal for integration with R Markdown and Quarto reports.
Usage
antibiogram(x, antibiotics = where(is.sir), mo_transform = "shortname",
ab_transform = "name", syndromic_group = NULL, add_total_n = FALSE,
only_all_tested = FALSE, digits = 0,
formatting_type = getOption("AMR_antibiogram_formatting_type",
ifelse(wisca, 18, 10)), col_mo = NULL, language = get_AMR_locale(),
minimum = 30, combine_SI = TRUE, sep = " + ", wisca = FALSE,
simulations = 1000, conf_interval = 0.95, interval_side = "two-tailed",
info = interactive())
wisca(x, antibiotics = where(is.sir), mo_transform = "shortname",
ab_transform = "name", syndromic_group = NULL, add_total_n = FALSE,
only_all_tested = FALSE, digits = 0,
formatting_type = getOption("AMR_antibiogram_formatting_type", 18),
col_mo = NULL, language = get_AMR_locale(), minimum = 30,
combine_SI = TRUE, sep = " + ", simulations = 1000,
info = interactive())
# S3 method for class 'antibiogram'
plot(x, ...)
# S3 method for class 'antibiogram'
autoplot(object, ...)
# S3 method for class 'antibiogram'
knit_print(x, italicise = TRUE,
na = getOption("knitr.kable.NA", default = ""), ...)Source
Bielicki JA et al. (2016). Selecting appropriate empirical antibiotic regimens for paediatric bloodstream infections: application of a Bayesian decision model to local and pooled antimicrobial resistance surveillance data Journal of Antimicrobial Chemotherapy 71(3); doi:10.1093/jac/dkv397
Bielicki JA et al. (2020). Evaluation of the coverage of 3 antibiotic regimens for neonatal sepsis in the hospital setting across Asian countries JAMA Netw Open. 3(2):e1921124; doi:10.1001.jamanetworkopen.2019.21124
Klinker KP et al. (2021). Antimicrobial stewardship and antibiograms: importance of moving beyond traditional antibiograms. Therapeutic Advances in Infectious Disease, May 5;8:20499361211011373; doi:10.1177/20499361211011373
Barbieri E et al. (2021). Development of a Weighted-Incidence Syndromic Combination Antibiogram (WISCA) to guide the choice of the empiric antibiotic treatment for urinary tract infection in paediatric patients: a Bayesian approach Antimicrobial Resistance & Infection Control May 1;10(1):74; doi:10.1186/s13756-021-00939-2
M39 Analysis and Presentation of Cumulative Antimicrobial Susceptibility Test Data, 5th Edition, 2022, Clinical and Laboratory Standards Institute (CLSI). https://clsi.org/standards/products/microbiology/documents/m39/.
Arguments
- x
a data.frame containing at least a column with microorganisms and columns with antimicrobial results (class 'sir', see
as.sir())- antibiotics
vector of any antimicrobial name or code (will be evaluated with
as.ab(), column name ofx, or (any combinations of) antimicrobial selectors such asaminoglycosides()orcarbapenems(). For combination antibiograms, this can also be set to values separated with"+", such as "TZP+TOB" or "cipro + genta", given that columns resembling such antimicrobials exist inx. See Examples.- mo_transform
a character to transform microorganism input - must be
"name","shortname"(default),"gramstain", or one of the column names of the microorganisms data set: "mo", "fullname", "status", "kingdom", "phylum", "class", "order", "family", "genus", "species", "subspecies", "rank", "ref", "oxygen_tolerance", "source", "lpsn", "lpsn_parent", "lpsn_renamed_to", "mycobank", "mycobank_parent", "mycobank_renamed_to", "gbif", "gbif_parent", "gbif_renamed_to", "prevalence", or "snomed". Can also beNULLto not transform the input.- ab_transform
a character to transform antimicrobial input - must be one of the column names of the antibiotics data set (defaults to
"name"): "ab", "cid", "name", "group", "atc", "atc_group1", "atc_group2", "abbreviations", "synonyms", "oral_ddd", "oral_units", "iv_ddd", "iv_units", or "loinc". Can also beNULLto not transform the input.- syndromic_group
a column name of
x, or values calculated to split rows ofx, e.g. by usingifelse()orcase_when(). See Examples.- add_total_n
a logical to indicate whether total available numbers per pathogen should be added to the table (default is
TRUE). This will add the lowest and highest number of available isolates per antimicrobial (e.g, if for E. coli 200 isolates are available for ciprofloxacin and 150 for amoxicillin, the returned number will be "150-200").- only_all_tested
(for combination antibiograms): a logical to indicate that isolates must be tested for all antimicrobials, see Details
- digits
number of digits to use for rounding the susceptibility percentage
- formatting_type
numeric value (1–22 for WISCA, 1-12 for non-WISCA) indicating how the 'cells' of the antibiogram table should be formatted. See Details > Formatting Type for a list of options.
- col_mo
column name of the names or codes of the microorganisms (see
as.mo()) - the default is the first column of classmo. Values will be coerced usingas.mo().- language
language to translate text, which defaults to the system language (see
get_AMR_locale())- minimum
the minimum allowed number of available (tested) isolates. Any isolate count lower than
minimumwill returnNAwith a warning. The default number of30isolates is advised by the Clinical and Laboratory Standards Institute (CLSI) as best practice, see Source.- combine_SI
a logical to indicate whether all susceptibility should be determined by results of either S, SDD, or I, instead of only S (default is
TRUE)- sep
a separating character for antimicrobial columns in combination antibiograms
- wisca
a logical to indicate whether a Weighted-Incidence Syndromic Combination Antibiogram (WISCA) must be generated (default is
FALSE). This will use a Bayesian hierarchical model to estimate regimen coverage probabilities using Montecarlo simulations. Setsimulationsto adjust.- simulations
(for WISCA) a numerical value to set the number of Montecarlo simulations
- conf_interval
(for WISCA) a numerical value to set confidence interval (default is
0.95)- interval_side
(for WISCA) the side of the confidence interval, either
"two-tailed"(default),"left"or"right"- info
a logical to indicate info should be printed - the default is
TRUEonly in interactive mode- ...
when used in R Markdown or Quarto: arguments passed on to
knitr::kable()(otherwise, has no use)- object
an
antibiogram()object- italicise
a logical to indicate whether the microorganism names in the knitr table should be made italic, using
italicise_taxonomy().- na
character to use for showing
NAvalues
Details
This function returns a table with values between 0 and 100 for susceptibility, not resistance.
Remember that you should filter your data to let it contain only first isolates! This is needed to exclude duplicates and to reduce selection bias. Use first_isolate() to determine them in your data set with one of the four available algorithms.
For estimating antimicrobial coverage, especially when creating a WISCA, the outcome might become more reliable by only including the top n species encountered in the data. You can filter on this top n using top_n_microorganisms(). For example, use top_n_microorganisms(your_data, n = 10) as a pre-processing step to only include the top 10 species in the data.
The numeric values of an antibiogram are stored in a long format as the attribute long_numeric. You can retrieve them using attributes(x)$long_numeric, where x is the outcome of antibiogram() or wisca(). This is ideal for e.g. advanced plotting.
Formatting Type
The formatting of the 'cells' of the table can be set with the argument formatting_type. In these examples, 5 is the susceptibility percentage (for WISCA: 4-6 indicates the confidence level), 15 the numerator, and 300 the denominator:
5
15
300
15/300
5 (300)
5% (300)
5 (N=300)
5% (N=300)
5 (15/300)
5% (15/300) - default for non-WISCA
5 (N=15/300)
5% (N=15/300)
Additional options for WISCA (using
antibiogram(..., wisca = TRUE)orwisca()):5 (4-6)
5% (4-6%)
5 (4-6,300)
5% (4-6%,300)
5 (4-6,N=300)
5% (4-6%,N=300) - default for WISCA
5 (4-6,15/300)
5% (4-6%,15/300)
5 (4-6,N=15/300)
5% (4-6%,N=15/300)
The default is 18 for WISCA and 10 for non-WISCA, which can be set globally with the package option AMR_antibiogram_formatting_type, e.g. options(AMR_antibiogram_formatting_type = 5).
Set digits (defaults to 0) to alter the rounding of the susceptibility percentages.
Antibiogram Types
There are various antibiogram types, as summarised by Klinker et al. (2021, doi:10.1177/20499361211011373
), and they are all supported by antibiogram().
Use WISCA whenever possible, since it provides more precise coverage estimates by accounting for pathogen incidence and antimicrobial susceptibility, as has been shown by Bielicki et al. (2020, doi:10.1001.jamanetworkopen.2019.21124 ). See the section Why Use WISCA? on this page.
Traditional Antibiogram
Case example: Susceptibility of Pseudomonas aeruginosa to piperacillin/tazobactam (TZP)
Code example:
antibiogram(your_data, antibiotics = "TZP")Combination Antibiogram
Case example: Additional susceptibility of Pseudomonas aeruginosa to TZP + tobramycin versus TZP alone
Code example:
antibiogram(your_data, antibiotics = c("TZP", "TZP+TOB", "TZP+GEN"))Syndromic Antibiogram
Case example: Susceptibility of Pseudomonas aeruginosa to TZP among respiratory specimens (obtained among ICU patients only)
Code example:
antibiogram(your_data, antibiotics = penicillins(), syndromic_group = "ward")Weighted-Incidence Syndromic Combination Antibiogram (WISCA)
WISCA can be applied to any antibiogram, see the section Why Use WISCA? on this page for more information.
Code example:
antibiogram(your_data, antibiotics = c("TZP", "TZP+TOB", "TZP+GEN"), wisca = TRUE) # this is equal to: wisca(your_data, antibiotics = c("TZP", "TZP+TOB", "TZP+GEN"))WISCA uses a sophisticated Bayesian decision model to combine both local and pooled antimicrobial resistance data. This approach not only evaluates local patterns but can also draw on multi-centre datasets to improve regimen accuracy, even in low-incidence infections like paediatric bloodstream infections (BSIs).
Grouped tibbles can also be used to calculate susceptibilities over various groups.
Code example:
Inclusion in Combination Antibiogram and Syndromic Antibiogram
Note that for types 2 and 3 (Combination Antibiogram and Syndromic Antibiogram), it is important to realise that susceptibility can be calculated in two ways, which can be set with the only_all_tested argument (default is FALSE). See this example for two antimicrobials, Drug A and Drug B, about how antibiogram() works to calculate the %SI:
--------------------------------------------------------------------
only_all_tested = FALSE only_all_tested = TRUE
----------------------- -----------------------
Drug A Drug B include as include as include as include as
numerator denominator numerator denominator
-------- -------- ---------- ----------- ---------- -----------
S or I S or I X X X X
R S or I X X X X
<NA> S or I X X - -
S or I R X X X X
R R - X - X
<NA> R - - - -
S or I <NA> X X - -
R <NA> - - - -
<NA> <NA> - - - -
--------------------------------------------------------------------Plotting
All types of antibiograms as listed above can be plotted (using ggplot2::autoplot() or base R's plot() and barplot()). As mentioned above, the numeric values of an antibiogram are stored in a long format as the attribute long_numeric. You can retrieve them using attributes(x)$long_numeric, where x is the outcome of antibiogram() or wisca().
The outcome of antibiogram() can also be used directly in R Markdown / Quarto (i.e., knitr) for reports. In this case, knitr::kable() will be applied automatically and microorganism names will even be printed in italics at default (see argument italicise).
You can also use functions from specific 'table reporting' packages to transform the output of antibiogram() to your needs, e.g. with flextable::as_flextable() or gt::gt().
Why Use WISCA?
WISCA, as outlined by Bielicki et al. (doi:10.1093/jac/dkv397 ), stands for Weighted-Incidence Syndromic Combination Antibiogram, which estimates the probability of adequate empirical antimicrobial regimen coverage for specific infection syndromes. This method leverages a Bayesian hierarchical logistic regression framework with random effects for pathogens and regimens, enabling robust estimates in the presence of sparse data.
The Bayesian model assumes conjugate priors for parameter estimation. For example, the coverage probability \(\theta\) for a given antimicrobial regimen is modelled using a Beta distribution as a prior:
$$\theta \sim \text{Beta}(\alpha_0, \beta_0)$$
where \(\alpha_0\) and \(\beta_0\) represent prior successes and failures, respectively, informed by expert knowledge or weakly informative priors (e.g., \(\alpha_0 = 1, \beta_0 = 1\)). The likelihood function is constructed based on observed data, where the number of covered cases for a regimen follows a binomial distribution:
$$y \sim \text{Binomial}(n, \theta)$$
Posterior parameter estimates are obtained by combining the prior and likelihood using Bayes' theorem. The posterior distribution of \(\theta\) is also a Beta distribution:
$$\theta | y \sim \text{Beta}(\alpha_0 + y, \beta_0 + n - y)$$
Pathogen incidence, representing the proportion of infections caused by different pathogens, is modelled using a Dirichlet distribution, which is the natural conjugate prior for multinomial outcomes. The Dirichlet distribution is parameterised by a vector of concentration parameters \(\alpha\), where each \(\alpha_i\) corresponds to a specific pathogen. The prior is typically chosen to be uniform (\(\alpha_i = 1\)), reflecting an assumption of equal prior probability across pathogens.
The posterior distribution of pathogen incidence is then given by:
$$\text{Dirichlet}(\alpha_1 + n_1, \alpha_2 + n_2, \dots, \alpha_K + n_K)$$
where \(n_i\) is the number of infections caused by pathogen \(i\) observed in the data. For practical implementation, pathogen incidences are sampled from their posterior using normalised Gamma-distributed random variables:
$$x_i \sim \text{Gamma}(\alpha_i + n_i, 1)$$ $$p_i = \frac{x_i}{\sum_{j=1}^K x_j}$$
where \(x_i\) represents unnormalised pathogen counts, and \(p_i\) is the normalised proportion for pathogen \(i\).
For hierarchical modelling, pathogen-level effects (e.g., differences in resistance patterns) and regimen-level effects are modelled using Gaussian priors on log-odds. This hierarchical structure ensures partial pooling of estimates across groups, improving stability in strata with small sample sizes. The model is implemented using Hamiltonian Monte Carlo (HMC) sampling.
Stratified results can be provided based on covariates such as age, sex, and clinical complexity (e.g., prior antimicrobial treatments or renal/urological comorbidities) using dplyr's group_by() as a pre-processing step before running wisca(). In this case, posterior odds ratios (ORs) are derived to quantify the effect of these covariates on coverage probabilities:
$$\text{OR}_{\text{covariate}} = \frac{\exp(\beta_{\text{covariate}})}{\exp(\beta_0)}$$
By combining empirical data with prior knowledge, WISCA overcomes the limitations of traditional combination antibiograms, offering disease-specific, patient-stratified estimates with robust uncertainty quantification. This tool is invaluable for antimicrobial stewardship programs and empirical treatment guideline refinement.
Examples
# example_isolates is a data set available in the AMR package.
# run ?example_isolates for more info.
example_isolates
#> # A tibble: 2,000 × 46
#> date patient age gender ward mo PEN OXA FLC AMX
#> <date> <chr> <dbl> <chr> <chr> <mo> <sir> <sir> <sir> <sir>
#> 1 2002-01-02 A77334 65 F Clinical B_ESCHR_COLI R NA NA NA
#> 2 2002-01-03 A77334 65 F Clinical B_ESCHR_COLI R NA NA NA
#> 3 2002-01-07 067927 45 F ICU B_STPHY_EPDR R NA R NA
#> 4 2002-01-07 067927 45 F ICU B_STPHY_EPDR R NA R NA
#> 5 2002-01-13 067927 45 F ICU B_STPHY_EPDR R NA R NA
#> 6 2002-01-13 067927 45 F ICU B_STPHY_EPDR R NA R NA
#> 7 2002-01-14 462729 78 M Clinical B_STPHY_AURS R NA S R
#> 8 2002-01-14 462729 78 M Clinical B_STPHY_AURS R NA S R
#> 9 2002-01-16 067927 45 F ICU B_STPHY_EPDR R NA R NA
#> 10 2002-01-17 858515 79 F ICU B_STPHY_EPDR R NA S NA
#> # ℹ 1,990 more rows
#> # ℹ 36 more variables: AMC <sir>, AMP <sir>, TZP <sir>, CZO <sir>, FEP <sir>,
#> # CXM <sir>, FOX <sir>, CTX <sir>, CAZ <sir>, CRO <sir>, GEN <sir>,
#> # TOB <sir>, AMK <sir>, KAN <sir>, TMP <sir>, SXT <sir>, NIT <sir>,
#> # FOS <sir>, LNZ <sir>, CIP <sir>, MFX <sir>, VAN <sir>, TEC <sir>,
#> # TCY <sir>, TGC <sir>, DOX <sir>, ERY <sir>, CLI <sir>, AZM <sir>,
#> # IPM <sir>, MEM <sir>, MTR <sir>, CHL <sir>, COL <sir>, MUP <sir>, …
# \donttest{
# Traditional antibiogram ----------------------------------------------
antibiogram(example_isolates,
antibiotics = c(aminoglycosides(), carbapenems())
)
#> ℹ For aminoglycosides() using columns 'GEN' (gentamicin), 'TOB'
#> (tobramycin), 'AMK' (amikacin), and 'KAN' (kanamycin)
#> ℹ For carbapenems() using columns 'IPM' (imipenem) and 'MEM' (meropenem)
#> # An Antibiogram (non-WISCA): 10 × 7
#> Pathogen Amikacin Gentamicin Imipenem Kanamycin Meropenem Tobramycin
#> * <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 CoNS 0% (0/43) 86% (267/… 52% (25… 0% (0/43) 52% (25/… 22% (12/5…
#> 2 E. coli 100% (171/… 98% (451/… 100% (4… NA 100% (41… 97% (450/…
#> 3 E. faecalis 0% (0/39) 0% (0/39) 100% (3… 0% (0/39) NA 0% (0/39)
#> 4 K. pneumoniae NA 90% (52/5… 100% (5… NA 100% (53… 90% (52/5…
#> 5 P. aeruginosa NA 100% (30/… NA 0% (0/30) NA 100% (30/…
#> 6 P. mirabilis NA 94% (32/3… 94% (30… NA NA 94% (32/3…
#> 7 S. aureus NA 99% (231/… NA NA NA 98% (84/8…
#> 8 S. epidermidis 0% (0/44) 79% (128/… NA 0% (0/44) NA 51% (45/8…
#> 9 S. hominis NA 92% (74/8… NA NA NA 85% (53/6…
#> 10 S. pneumoniae 0% (0/117) 0% (0/117) NA 0% (0/11… NA 0% (0/117)
#> # Use `plot()` or `ggplot2::autoplot()` to create a plot of this antibiogram,
#> # or use it directly in R Markdown or https://quarto.org, see ?antibiogram
antibiogram(example_isolates,
antibiotics = aminoglycosides(),
ab_transform = "atc",
mo_transform = "gramstain"
)
#> ℹ For aminoglycosides() using columns 'GEN' (gentamicin), 'TOB'
#> (tobramycin), 'AMK' (amikacin), and 'KAN' (kanamycin)
#> # An Antibiogram (non-WISCA): 2 × 5
#> Pathogen J01GB01 J01GB03 J01GB04 J01GB06
#> * <chr> <chr> <chr> <chr> <chr>
#> 1 Gram-negative 96% (658/686) 96% (659/684) 0% (0/35) 98% (251/256)
#> 2 Gram-positive 34% (228/665) 63% (740/1170) 0% (0/436) 0% (0/436)
#> # Use `plot()` or `ggplot2::autoplot()` to create a plot of this antibiogram,
#> # or use it directly in R Markdown or https://quarto.org, see ?antibiogram
antibiogram(example_isolates,
antibiotics = carbapenems(),
ab_transform = "name",
mo_transform = "name"
)
#> ℹ For carbapenems() using columns 'IPM' (imipenem) and 'MEM' (meropenem)
#> # An Antibiogram (non-WISCA): 5 × 3
#> Pathogen Imipenem Meropenem
#> * <chr> <chr> <chr>
#> 1 Coagulase-negative Staphylococcus (CoNS) 52% (25/48) 52% (25/48)
#> 2 Enterococcus faecalis 100% (38/38) NA
#> 3 Escherichia coli 100% (422/422) 100% (418/418)
#> 4 Klebsiella pneumoniae 100% (51/51) 100% (53/53)
#> 5 Proteus mirabilis 94% (30/32) NA
#> # Use `plot()` or `ggplot2::autoplot()` to create a plot of this antibiogram,
#> # or use it directly in R Markdown or https://quarto.org, see ?antibiogram
# Combined antibiogram -------------------------------------------------
# combined antibiotics yield higher empiric coverage
antibiogram(example_isolates,
antibiotics = c("TZP", "TZP+TOB", "TZP+GEN"),
mo_transform = "gramstain"
)
#> # An Antibiogram (non-WISCA): 2 × 4
#> Pathogen Piperacillin/tazobac…¹ Piperacillin/tazobac…² Piperacillin/tazobac…³
#> * <chr> <chr> <chr> <chr>
#> 1 Gram-neg… 88% (565/641) 99% (681/691) 98% (679/693)
#> 2 Gram-pos… 86% (296/345) 98% (1018/1044) 95% (524/550)
#> # ℹ abbreviated names: ¹`Piperacillin/tazobactam`,
#> # ²`Piperacillin/tazobactam + Gentamicin`,
#> # ³`Piperacillin/tazobactam + Tobramycin`
#> # Use `plot()` or `ggplot2::autoplot()` to create a plot of this antibiogram,
#> # or use it directly in R Markdown or https://quarto.org, see ?antibiogram
# names of antibiotics do not need to resemble columns exactly:
antibiogram(example_isolates,
antibiotics = c("Cipro", "cipro + genta"),
mo_transform = "gramstain",
ab_transform = "name",
sep = " & "
)
#> # An Antibiogram (non-WISCA): 2 × 3
#> Pathogen Ciprofloxacin `Ciprofloxacin & Gentamicin`
#> * <chr> <chr> <chr>
#> 1 Gram-negative 91% (621/684) 99% (684/694)
#> 2 Gram-positive 77% (560/724) 93% (784/847)
#> # Use `plot()` or `ggplot2::autoplot()` to create a plot of this antibiogram,
#> # or use it directly in R Markdown or https://quarto.org, see ?antibiogram
# Syndromic antibiogram ------------------------------------------------
# the data set could contain a filter for e.g. respiratory specimens
antibiogram(example_isolates,
antibiotics = c(aminoglycosides(), carbapenems()),
syndromic_group = "ward"
)
#> ℹ For aminoglycosides() using columns 'GEN' (gentamicin), 'TOB'
#> (tobramycin), 'AMK' (amikacin), and 'KAN' (kanamycin)
#> ℹ For carbapenems() using columns 'IPM' (imipenem) and 'MEM' (meropenem)
#> # An Antibiogram (non-WISCA): 14 × 8
#> `Syndromic Group` Pathogen Amikacin Gentamicin Imipenem Kanamycin Meropenem
#> * <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 Clinical CoNS NA 89% (183/… 57% (20… NA 57% (20/…
#> 2 ICU CoNS NA 79% (58/7… NA NA NA
#> 3 Outpatient CoNS NA 84% (26/3… NA NA NA
#> 4 Clinical E. coli 100% (1… 98% (291/… 100% (2… NA 100% (27…
#> 5 ICU E. coli 100% (5… 99% (135/… 100% (1… NA 100% (11…
#> 6 Clinical K. pneumo… NA 92% (47/5… 100% (4… NA 100% (46…
#> 7 Clinical P. mirabi… NA 100% (30/… NA NA NA
#> 8 Clinical S. aureus NA 99% (148/… NA NA NA
#> 9 ICU S. aureus NA 100% (66/… NA NA NA
#> 10 Clinical S. epider… NA 82% (65/7… NA NA NA
#> 11 ICU S. epider… NA 72% (54/7… NA NA NA
#> 12 Clinical S. hominis NA 96% (43/4… NA NA NA
#> 13 Clinical S. pneumo… 0% (0/7… 0% (0/78) NA 0% (0/78) NA
#> 14 ICU S. pneumo… 0% (0/3… 0% (0/30) NA 0% (0/30) NA
#> # ℹ 1 more variable: Tobramycin <chr>
#> # Use `plot()` or `ggplot2::autoplot()` to create a plot of this antibiogram,
#> # or use it directly in R Markdown or https://quarto.org, see ?antibiogram
# now define a data set with only E. coli
ex1 <- example_isolates[which(mo_genus() == "Escherichia"), ]
#> ℹ Using column 'mo' as input for mo_genus()
# with a custom language, though this will be determined automatically
# (i.e., this table will be in Spanish on Spanish systems)
antibiogram(ex1,
antibiotics = aminoglycosides(),
ab_transform = "name",
syndromic_group = ifelse(ex1$ward == "ICU",
"UCI", "No UCI"
),
language = "es"
)
#> ℹ For aminoglycosides() using columns 'GEN' (gentamicin), 'TOB'
#> (tobramycin), 'AMK' (amikacin), and 'KAN' (kanamycin)
#> # An Antibiogram (non-WISCA): 2 × 5
#> `Grupo sindrómico` Patógeno Amikacina Gentamicina Tobramicina
#> * <chr> <chr> <chr> <chr> <chr>
#> 1 No UCI E. coli 100% (119/119) 98% (316/323) 98% (318/325)
#> 2 UCI E. coli 100% (52/52) 99% (135/137) 96% (132/137)
#> # Use `plot()` or `ggplot2::autoplot()` to create a plot of this antibiogram,
#> # or use it directly in R Markdown or https://quarto.org, see ?antibiogram
# WISCA antibiogram ----------------------------------------------------
# can be used for any of the above types - just add `wisca = TRUE`
antibiogram(example_isolates,
antibiotics = c("TZP", "TZP+TOB", "TZP+GEN"),
mo_transform = "gramstain",
wisca = TRUE
)
#> # An Antibiogram (WISCA / 95% CI): 2 × 4
#> Pathogen Piperacillin/tazobac…¹ Piperacillin/tazobac…² Piperacillin/tazobac…³
#> * <chr> <chr> <chr> <chr>
#> 1 Gram-neg… 88% (85-90%,N=641) 98% (97-99%,N=691) 98% (97-99%,N=693)
#> 2 Gram-pos… 86% (82-89%,N=345) 97% (96-98%,N=1044) 95% (93-97%,N=550)
#> # ℹ abbreviated names: ¹`Piperacillin/tazobactam`,
#> # ²`Piperacillin/tazobactam + Gentamicin`,
#> # ³`Piperacillin/tazobactam + Tobramycin`
#> # Use `plot()` or `ggplot2::autoplot()` to create a plot of this antibiogram,
#> # or use it directly in R Markdown or https://quarto.org, see ?antibiogram
# Print the output for R Markdown / Quarto -----------------------------
ureido <- antibiogram(example_isolates,
antibiotics = ureidopenicillins(),
ab_transform = "name",
wisca = TRUE
)
#> ℹ For ureidopenicillins() using column 'TZP' (piperacillin/tazobactam)
# in an Rmd file, you would just need to return `ureido` in a chunk,
# but to be explicit here:
if (requireNamespace("knitr")) {
cat(knitr::knit_print(ureido))
}
#>
#>
#> |Pathogen |Piperacillin/tazobactam |
#> |:---------------|:-----------------------|
#> |*B. fragilis* |5% (0-17%,N=20) |
#> |CoNS |32% (17-47%,N=33) |
#> |*E. cloacae* |73% (51-88%,N=20) |
#> |*E. coli* |94% (92-96%,N=416) |
#> |*E. faecalis* |95% (82-100%,N=18) |
#> |*E. faecium* |10% (1-26%,N=18) |
#> |GBS |95% (84-100%,N=18) |
#> |*K. pneumoniae* |87% (78-95%,N=53) |
#> |*P. aeruginosa* |97% (88-100%,N=27) |
#> |*P. mirabilis* |97% (88-100%,N=27) |
#> |*S. anginosus* |94% (80-100%,N=16) |
#> |*S. marcescens* |50% (32-69%,N=22) |
#> |*S. pneumoniae* |99% (97-100%,N=112) |
#> |*S. pyogenes* |95% (81-100%,N=16) |
# Generate plots with ggplot2 or base R --------------------------------
ab1 <- antibiogram(example_isolates,
antibiotics = c("AMC", "CIP", "TZP", "TZP+TOB"),
mo_transform = "gramstain",
wisca = TRUE
)
ab2 <- antibiogram(example_isolates,
antibiotics = c("AMC", "CIP", "TZP", "TZP+TOB"),
mo_transform = "gramstain",
syndromic_group = "ward"
)
if (requireNamespace("ggplot2")) {
ggplot2::autoplot(ab1)
}
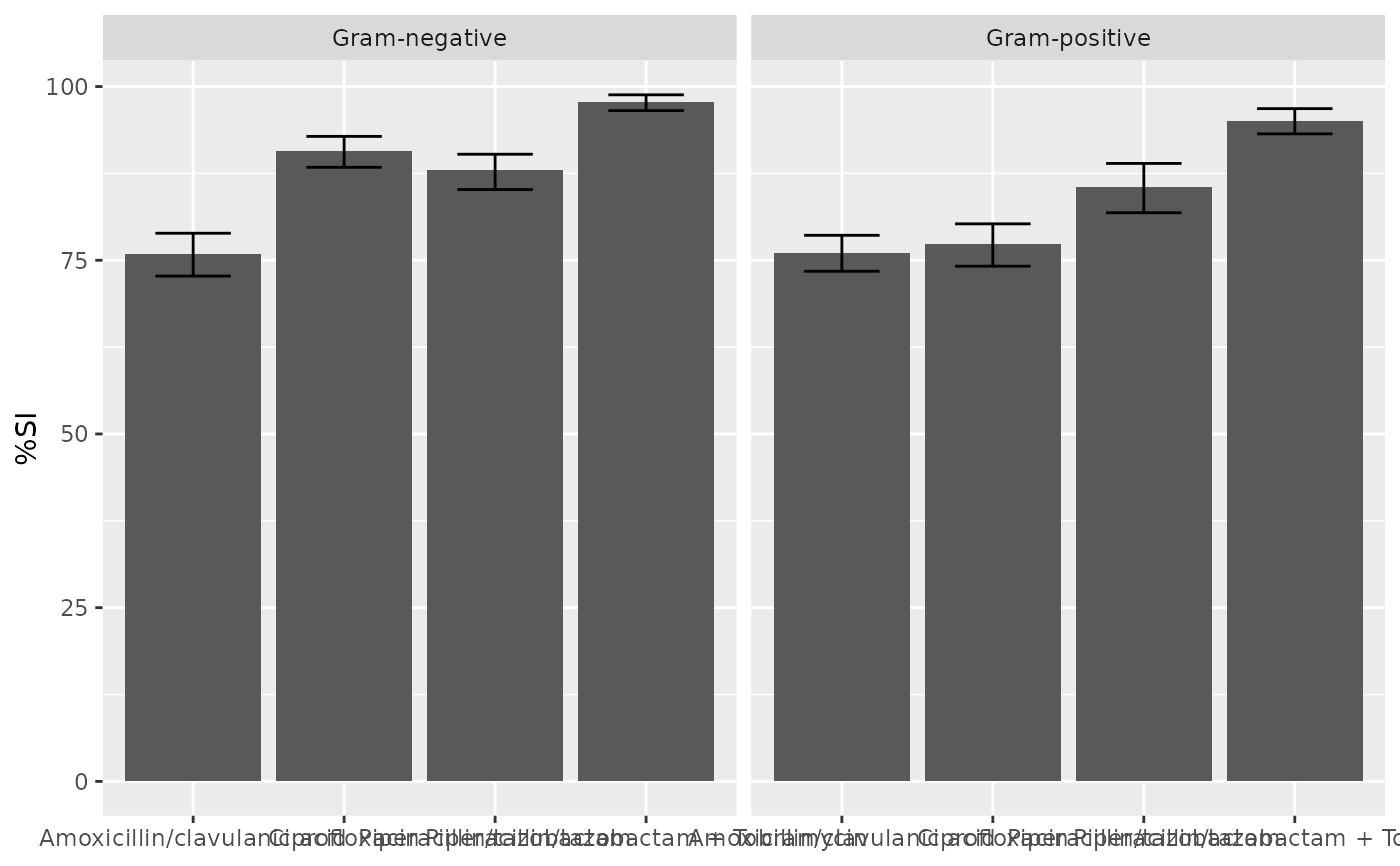 if (requireNamespace("ggplot2")) {
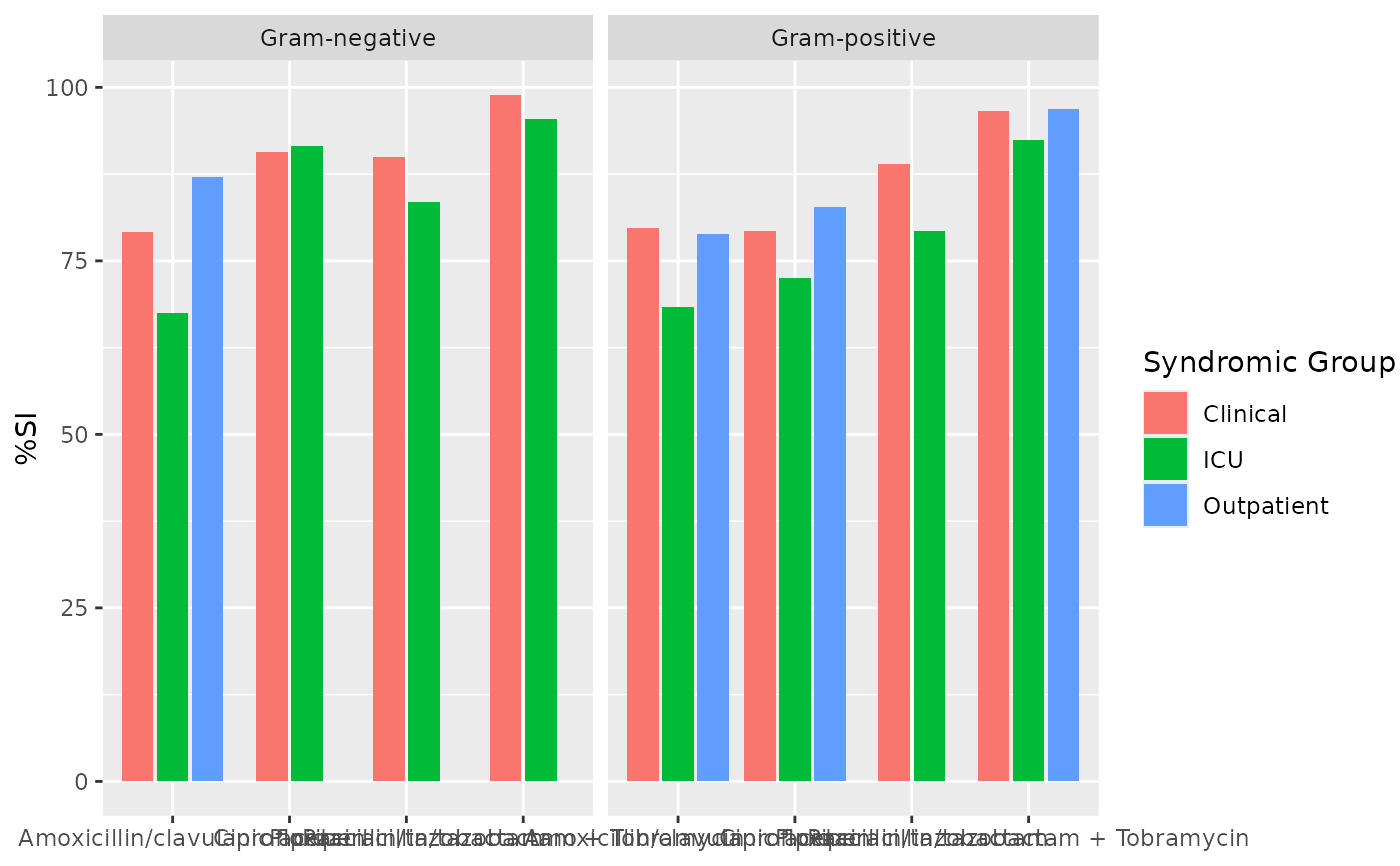
ggplot2::autoplot(ab2)
}
if (requireNamespace("ggplot2")) {
ggplot2::autoplot(ab2)
}
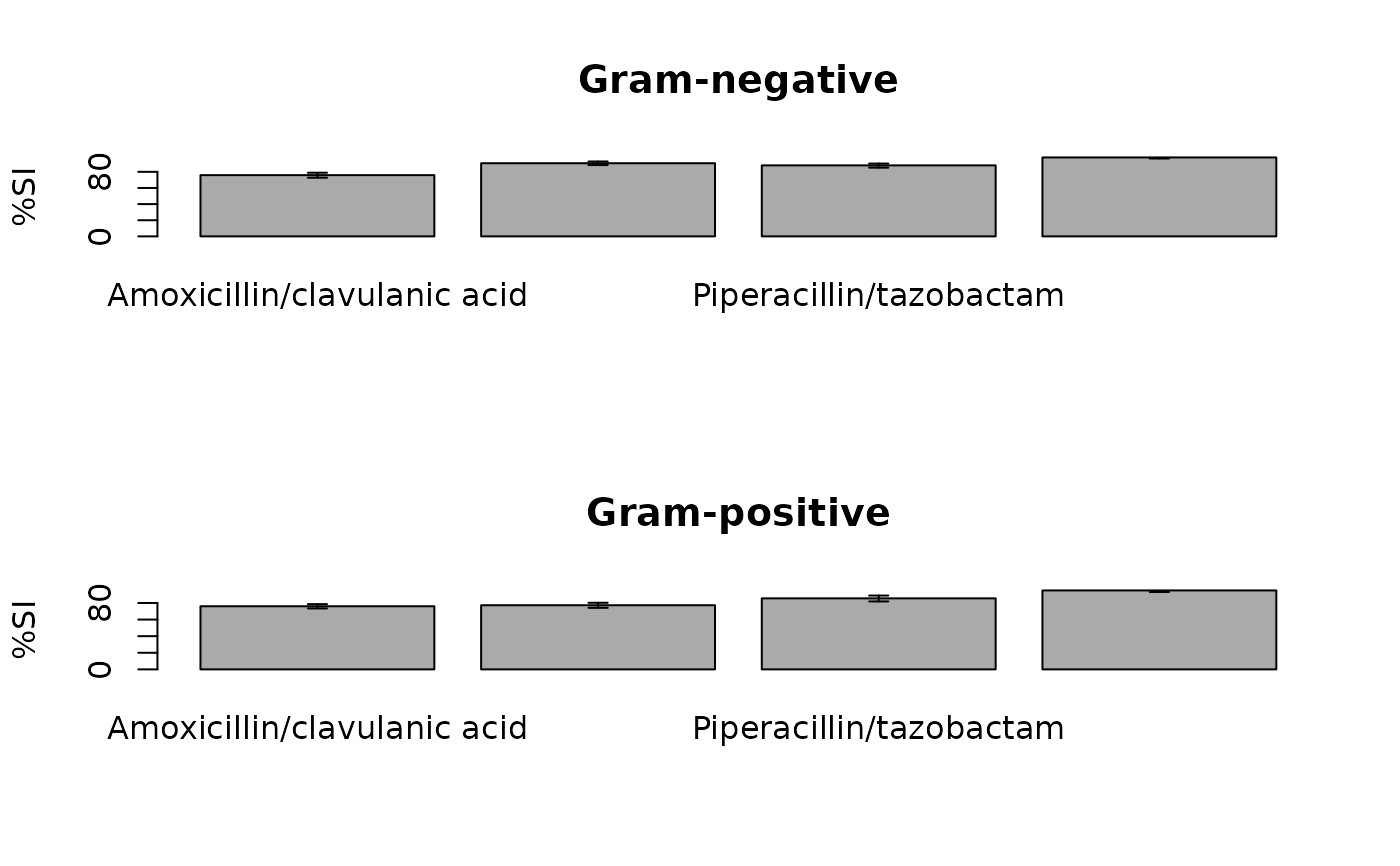
 plot(ab1)
plot(ab1)
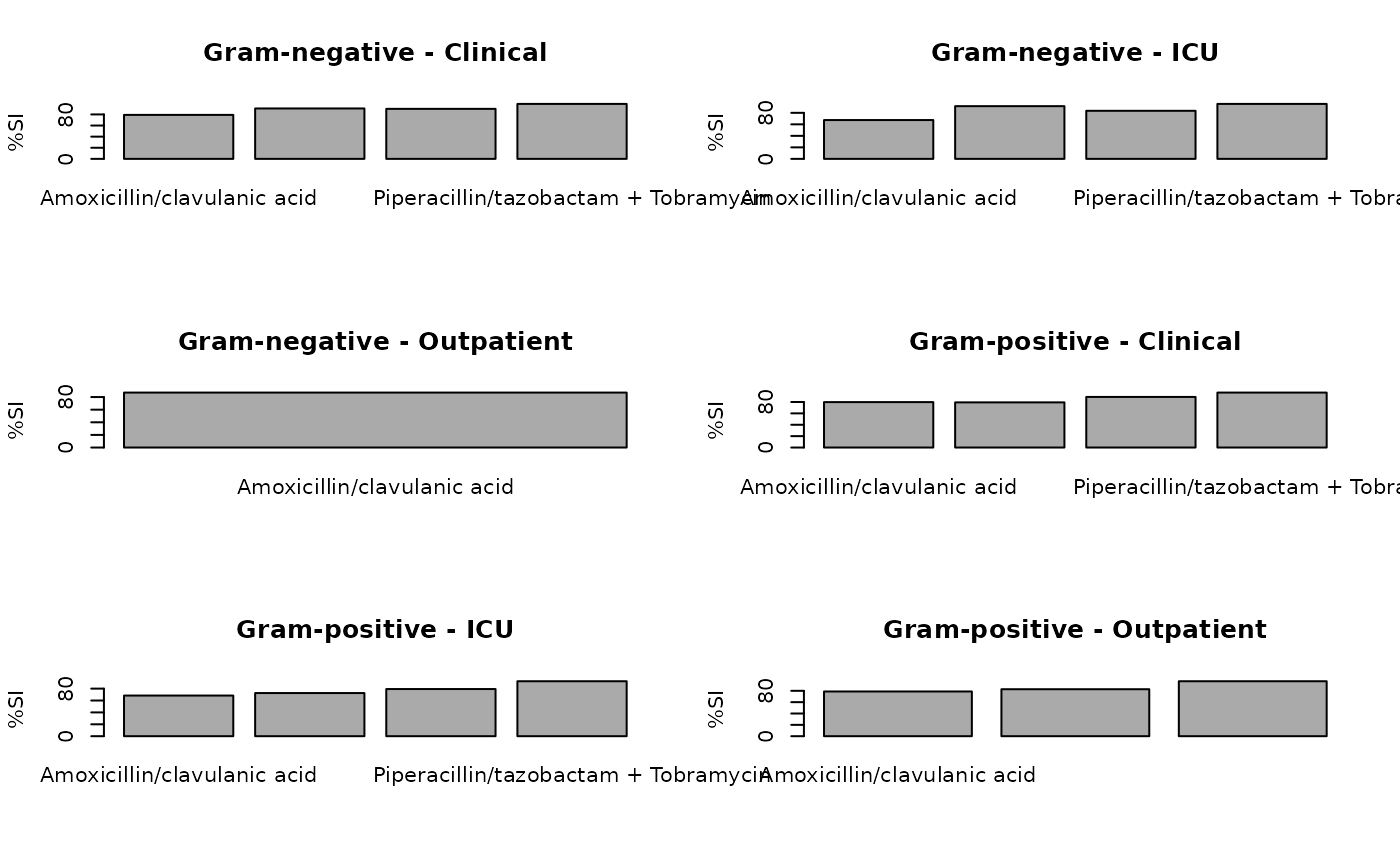
 plot(ab2)
plot(ab2)
 # }
# }