One of the most important features of this package is the complete microbial taxonomic database, supplied by the Catalogue of Life (CoL) and the List of Prokaryotic names with Standing in Nomenclature (LPSN). We created a function as.mo() that transforms any user input value to a valid microbial ID by using intelligent rules combined with the microbial taxonomy.
Using the microbenchmark package, we can review the calculation performance of this function. Its function microbenchmark() runs different input expressions independently of each other and measures their time-to-result.
In the next test, we try to ‘coerce’ different input values into the microbial code of Staphylococcus aureus. Coercion is a computational process of forcing output based on an input. For microorganism names, coercing user input to taxonomically valid microorganism names is crucial to ensure correct interpretation and to enable grouping based on taxonomic properties.
The actual result is the same every time: it returns its microorganism code B_STPHY_AURS (B stands for Bacteria, its taxonomic kingdom).
But the calculation time differs a lot:
S.aureus <- microbenchmark( as.mo("sau"), # WHONET code as.mo("stau"), as.mo("STAU"), as.mo("staaur"), as.mo("STAAUR"), as.mo("S. aureus"), as.mo("S aureus"), as.mo("Staphylococcus aureus"), # official taxonomic name as.mo("Staphylococcus aureus (MRSA)"), # additional text as.mo("Sthafilokkockus aaureuz"), # incorrect spelling as.mo("MRSA"), # Methicillin Resistant S. aureus as.mo("VISA"), # Vancomycin Intermediate S. aureus times = 25) print(S.aureus, unit = "ms", signif = 2) # Unit: milliseconds # expr min lq mean median uq max neval # as.mo("sau") 25.0 25.0 30 26.0 26.0 83 25 # as.mo("stau") 120.0 130.0 150 130.0 180.0 390 25 # as.mo("STAU") 120.0 130.0 150 130.0 180.0 190 25 # as.mo("staaur") 25.0 26.0 33 26.0 26.0 83 25 # as.mo("STAAUR") 25.0 26.0 33 26.0 26.0 83 25 # as.mo("S. aureus") 66.0 66.0 89 67.0 120.0 150 25 # as.mo("S aureus") 66.0 66.0 74 66.0 67.0 120 25 # as.mo("Staphylococcus aureus") 6.8 6.9 14 6.9 7.5 63 25 # as.mo("Staphylococcus aureus (MRSA)") 550.0 550.0 560 550.0 560.0 620 25 # as.mo("Sthafilokkockus aaureuz") 410.0 420.0 430 420.0 420.0 620 25 # as.mo("MRSA") 25.0 26.0 31 26.0 26.0 83 25 # as.mo("VISA") 46.0 47.0 65 47.0 98.0 110 25
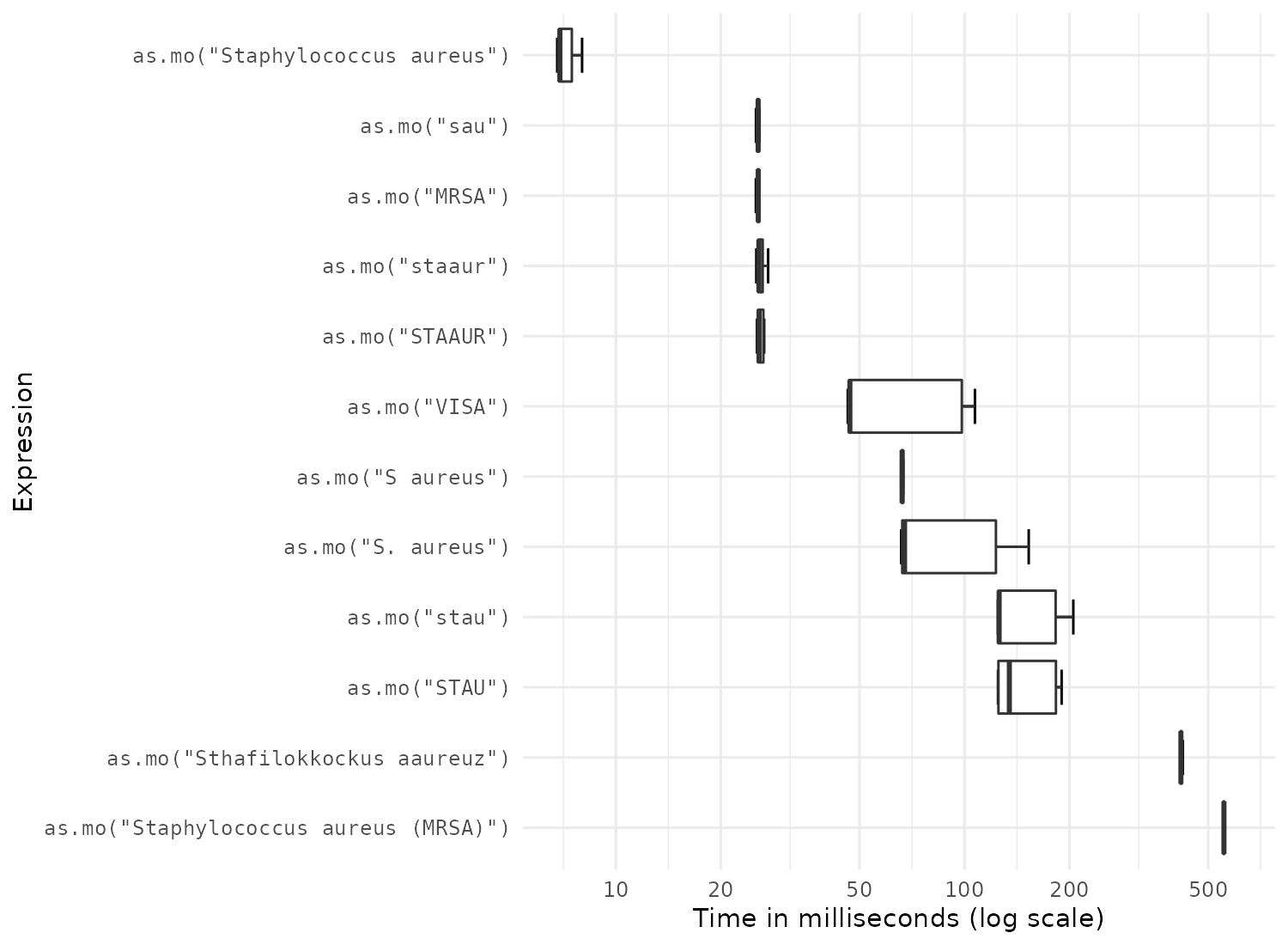
In the table above, all measurements are shown in milliseconds (thousands of seconds). A value of 5 milliseconds means it can determine 200 input values per second. It case of 200 milliseconds, this is only 5 input values per second. It is clear that accepted taxonomic names are extremely fast, but some variations are up to 200 times slower to determine.
To improve performance, we implemented two important algorithms to save unnecessary calculations: repetitive results and already precalculated results.
Repetitive results
Repetitive results are values that are present more than once in a vector. Unique values will only be calculated once by as.mo(). So running as.mo(c("E. coli", "E. coli")) will check the value "E. coli" only once.
To prove this, we will use mo_name() for testing - a helper function that returns the full microbial name (genus, species and possibly subspecies) which uses as.mo() internally.
# start with the example_isolates data set x <- example_isolates %>% # take all MO codes from the 'mo' column pull(mo) %>% # and copy them a thousand times rep(1000) %>% # then scramble them sample() # what do these values look like? They are of class <mo>: head(x) # Class <mo> # [1] B_STPHY_EPDR B_STPHY_EPDR B_STPHY_CONS B_STPHY_CONS B_STPHY_EPDR # [6] B_ESCHR_COLI # as the example_isolates data set has 2,000 rows, we should have 2 million items length(x) # [1] 2000000 # and how many unique values do we have? n_distinct(x) # [1] 90 # now let's see: run_it <- microbenchmark(mo_name(x), times = 10) print(run_it, unit = "ms", signif = 3) # Unit: milliseconds # expr min lq mean median uq max neval # mo_name(x) 321 378 443 410 438 713 10
So getting official taxonomic names of 2,000,000 (!!) items consisting of 90 unique values only takes 0.41 seconds. That is 205 nanoseconds on average. You only lose time on your unique input values.
Precalculated results
What about precalculated results? If the input is an already precalculated result of a helper function such as mo_name(), it almost doesn’t take any time at all. In other words, if you run mo_name() on a valid taxonomic name, it will return the results immediately (see ‘C’ below):
run_it <- microbenchmark(A = mo_name("STAAUR"), B = mo_name("S. aureus"), C = mo_name("Staphylococcus aureus"), times = 10) print(run_it, unit = "ms", signif = 3) # Unit: milliseconds # expr min lq mean median uq max neval # A 17.00 17.1 17.10 17.10 17.20 17.20 10 # B 57.20 57.3 68.90 57.60 58.40 117.00 10 # C 3.66 3.7 3.74 3.74 3.77 3.89 10
So going from mo_name("Staphylococcus aureus") to "Staphylococcus aureus" takes 0.0037 seconds - it doesn’t even start calculating if the result would be the same as the expected resulting value. That goes for all helper functions:
run_it <- microbenchmark(A = mo_species("aureus"), B = mo_genus("Staphylococcus"), C = mo_name("Staphylococcus aureus"), D = mo_family("Staphylococcaceae"), E = mo_order("Bacillales"), F = mo_class("Bacilli"), G = mo_phylum("Firmicutes"), H = mo_kingdom("Bacteria"), times = 10) print(run_it, unit = "ms", signif = 3) # Unit: milliseconds # expr min lq mean median uq max neval # A 3.70 3.71 3.81 3.74 3.82 4.14 10 # B 3.66 3.67 3.76 3.69 3.76 4.10 10 # C 3.66 3.70 3.72 3.72 3.73 3.76 10 # D 3.63 3.67 3.77 3.71 3.88 4.09 10 # E 3.62 3.67 3.75 3.70 3.78 4.07 10 # F 3.62 3.64 3.66 3.65 3.65 3.74 10 # G 3.63 3.64 3.67 3.67 3.68 3.75 10 # H 3.63 3.64 3.74 3.67 3.84 4.07 10
Of course, when running mo_phylum("Firmicutes") the function has zero knowledge about the actual microorganism, namely S. aureus. But since the result would be "Firmicutes" anyway, there is no point in calculating the result. And because this package contains all phyla of all known bacteria, it can just return the initial value immediately.
Results in other languages
When the system language is non-English and supported by this AMR package, some functions will have a translated result. This almost does’t take extra time:
mo_name("CoNS", language = "en") # or just mo_name("CoNS") on an English system # [1] "Coagulase-negative Staphylococcus (CoNS)" mo_name("CoNS", language = "es") # or just mo_name("CoNS") on a Spanish system # [1] "Staphylococcus coagulasa negativo (SCN)" mo_name("CoNS", language = "nl") # or just mo_name("CoNS") on a Dutch system # [1] "Coagulase-negatieve Staphylococcus (CNS)" run_it <- microbenchmark(en = mo_name("CoNS", language = "en"), de = mo_name("CoNS", language = "de"), nl = mo_name("CoNS", language = "nl"), es = mo_name("CoNS", language = "es"), it = mo_name("CoNS", language = "it"), fr = mo_name("CoNS", language = "fr"), pt = mo_name("CoNS", language = "pt"), times = 100) print(run_it, unit = "ms", signif = 4) # Unit: milliseconds # expr min lq mean median uq max neval # en 43.15 43.49 48.88 43.66 43.81 122.3 100 # de 79.59 80.39 88.27 80.89 81.11 135.8 100 # nl 79.69 80.45 87.16 80.81 81.07 136.6 100 # es 79.28 80.12 89.84 80.51 81.02 159.5 100 # it 51.74 52.20 55.59 52.39 52.61 109.1 100 # fr 51.43 51.88 54.83 52.05 52.29 105.5 100 # pt 51.58 51.93 59.25 52.28 52.55 111.8 100
Currently supported non-English languages are German, Dutch, Spanish, Italian, French and Portuguese.