Benchmarks
Matthijs S. Berends
14 February 2019
benchmarks.RmdOne of the most important features of this package is the complete microbial taxonomic database, supplied by ITIS (https://www.itis.gov). We created a function as.mo() that transforms any user input value to a valid microbial ID by using AI (Artificial Intelligence) and based on the taxonomic tree of ITIS.
Using the microbenchmark package, we can review the calculation performance of this function. Its function microbenchmark() calculates different input expressions independently of each others and runs every expression 100 times.
In the next test, we try to ‘coerce’ different input values for Staphylococcus aureus. The actual result is the same every time: it returns its MO code B_STPHY_AUR (B stands for Bacteria, the taxonomic kingdom).
But the calculation time differs a lot. Here, the AI effect can be reviewed best:
benchmark <- microbenchmark(as.mo("sau"),
as.mo("stau"),
as.mo("staaur"),
as.mo("S. aureus"),
as.mo("S. aureus"),
as.mo("STAAUR"),
as.mo("Staphylococcus aureus"),
as.mo("B_STPHY_AUR"))
print(benchmark, unit = "ms")
# Unit: milliseconds
# expr min lq mean median uq max neval
# as.mo("sau") 18.983141 19.121148 19.9676944 19.1967505 19.2871260 38.635012 100
# as.mo("stau") 37.503863 37.692049 38.9856547 37.8244335 37.9851040 57.576107 100
# as.mo("staaur") 18.945427 19.122579 19.6392560 19.2241285 19.3536140 38.687672 100
# as.mo("S. aureus") 15.305229 15.471103 16.3477096 15.5545630 15.6689280 36.363005 100
# as.mo("S. aureus") 15.308232 15.469881 16.5269706 15.5506870 15.6277560 42.155292 100
# as.mo("STAAUR") 18.984049 19.117166 19.6104597 19.2219285 19.3161095 38.638783 100
# as.mo("Staphylococcus aureus") 8.103546 8.198285 8.6422018 8.2636915 8.3200535 27.002527 100
# as.mo("B_STPHY_AUR") 0.156236 0.196779 0.2017926 0.2035535 0.2115505 0.241861 100
par(mar = c(5, 15, 4, 2)) # set more space for left margin text (15)
boxplot(benchmark, horizontal = TRUE, las = 1, unit = "ms", log = FALSE, xlab = "", ylim = c(0, 200),
main = expression(paste("Benchmark of ", italic("Staphylococcus aureus"))))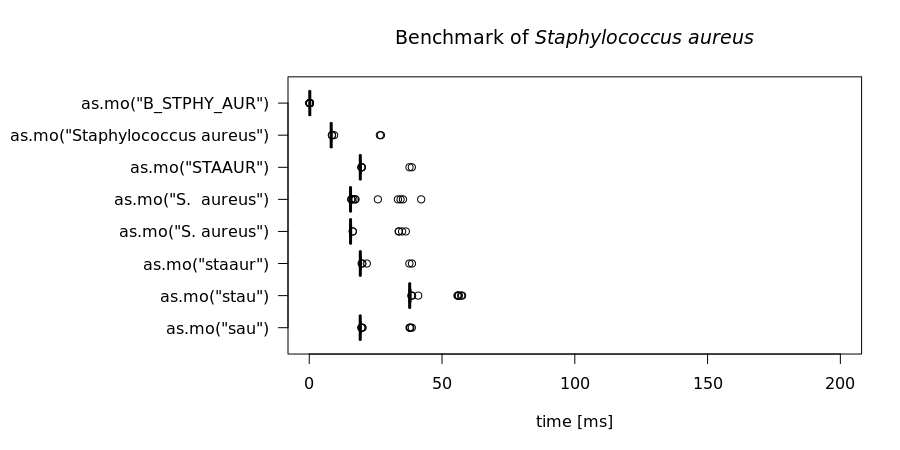
In the table above, all measurements are shown in milliseconds (thousands of seconds), tested on a quite regular Linux server from 2007 (Core 2 Duo 2.7 GHz, 2 GB DDR2 RAM). A value of 8 milliseconds means it can determine 125 input values per second. It case of 40 milliseconds, this is only 25 input values per second. The more an input value resembles a full name, the faster the result will be found. In case of as.mo("B_STPHY_AUR"), the input is already a valid MO code, so it only almost takes no time at all (0.0002 seconds on our server).
To achieve this speed, the as.mo function also takes into account the prevalence of human pathogenic microorganisms. The downside is of course that less prevalent microorganisms will be determined far less faster. See this example for the ID of Burkholderia nodosa (B_BRKHL_NOD):
benchmark <- microbenchmark(as.mo("buno"),
as.mo("burnod"),
as.mo("B. nodosa"),
as.mo("B. nodosa"),
as.mo("BURNOD"),
as.mo("Burkholderia nodosa"),
as.mo("B_BRKHL_NOD"))
print(benchmark, unit = "ms")
# Unit: milliseconds
# expr min lq mean median uq max neval
# as.mo("buno") 125.141333 125.8553210 129.5727691 126.3899910 127.0954925 194.51985 100
# as.mo("burnod") 142.300359 144.1611750 147.0642288 144.6074960 145.5243025 176.91649 100
# as.mo("B. nodosa") 81.530132 81.9360840 83.3915418 82.1852770 82.6848870 102.63184 100
# as.mo("B. nodosa") 81.109547 81.9836805 84.7595894 82.3437825 82.8282705 110.67036 100
# as.mo("BURNOD") 143.163527 143.9134485 148.7192688 144.5582580 145.7489115 314.92070 100
# as.mo("Burkholderia nodosa") 36.226325 36.5499000 37.1309929 36.6581540 36.7551985 56.25597 100
# as.mo("B_BRKHL_NOD") 0.172509 0.3038455 0.4806591 0.3078265 0.3121215 19.16173 100
boxplot(benchmark, horizontal = TRUE, las = 1, unit = "ms", log = FALSE, xlab = "", ylim = c(0, 200),
main = expression(paste("Benchmark of ", italic("Burkholderia nodosa"))))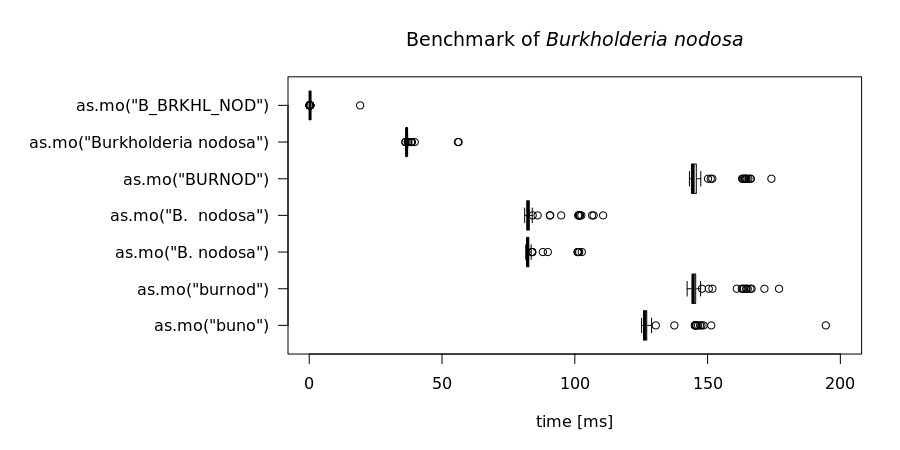
That takes up to 8 times as much time! A value of 145 milliseconds means it can only determine ~7 different input values per second. We can conclude that looking up arbitrary codes of less prevalent microorganisms is the worst way to go, in terms of calculation performance.
To relieve this pitfall and further improve performance, two important calculations take almost no time at all: repetitive results and already precalculated results.
Repetitive results
Repetitive results mean that unique values are present more than once. Unique values will only be calculated once by as.mo(). We will use mo_fullname() for this test - a helper function that returns the full microbial name (genus, species and possibly subspecies) and uses as.mo() internally.
library(dplyr)
# take 500,000 random MO codes from the septic_patients data set
x = septic_patients %>%
sample_n(500000, replace = TRUE) %>%
pull(mo)
# got the right length?
length(x)
# [1] 500000
# and how many unique values do we have?
n_distinct(x)
# [1] 96
# only 96, but distributed in 500,000 results. now let's see:
microbenchmark(X = mo_fullname(x),
times = 10,
unit = "ms")
# Unit: milliseconds
# expr min lq mean median uq max neval
# X 114.9342 117.1076 129.6448 120.2047 131.5005 168.6371 10So transforming 500,000 values (!) of 96 unique values only takes 0.12 seconds (120 ms). You only lose time on your unique input values.
Results of a tenfold - 5,000,000 values:
# Unit: milliseconds
# expr min lq mean median uq max neval
# X 882.9045 901.3011 1001.677 940.3421 1168.088 1226.846 10Even determining the full names of 5 Million values is done within a second.
Precalculated results
What about precalculated results? If the input is an already precalculated result of a helper function like mo_fullname(), it almost doesn’t take any time at all (see ‘C’ below):
microbenchmark(A = mo_fullname("B_STPHY_AUR"),
B = mo_fullname("S. aureus"),
C = mo_fullname("Staphylococcus aureus"),
times = 10,
unit = "ms")
# Unit: milliseconds
# expr min lq mean median uq max neval
# A 11.364086 11.460537 11.5104799 11.4795330 11.524860 11.818263 10
# B 11.976454 12.012352 12.1704592 12.0853020 12.210004 12.881737 10
# C 0.095823 0.102528 0.1167754 0.1153785 0.132629 0.140661 10So going from mo_fullname("Staphylococcus aureus") to "Staphylococcus aureus" takes 0.0001 seconds - it doesn’t even start calculating if the result would be the same as the expected resulting value. That goes for all helper functions:
microbenchmark(A = mo_species("aureus"),
B = mo_genus("Staphylococcus"),
C = mo_fullname("Staphylococcus aureus"),
D = mo_family("Staphylococcaceae"),
E = mo_order("Bacillales"),
F = mo_class("Bacilli"),
G = mo_phylum("Firmicutes"),
H = mo_subkingdom("Posibacteria"),
I = mo_kingdom("Bacteria"),
times = 10,
unit = "ms")
# Unit: milliseconds
# expr min lq mean median uq max neval
# A 0.105181 0.121314 0.1478538 0.1465265 0.166711 0.211409 10
# B 0.132558 0.146388 0.1584278 0.1499835 0.164895 0.208477 10
# C 0.135492 0.160355 0.2341847 0.1884665 0.348857 0.395931 10
# D 0.109650 0.115727 0.1270481 0.1264130 0.128648 0.168317 10
# E 0.081574 0.096940 0.0992582 0.0980915 0.101479 0.120477 10
# F 0.081575 0.088489 0.0988463 0.0989650 0.103365 0.126482 10
# G 0.091981 0.095333 0.1043568 0.1001530 0.111327 0.129625 10
# H 0.092610 0.093169 0.1009135 0.0985455 0.101828 0.120406 10
# I 0.087371 0.091213 0.1069758 0.0941815 0.109302 0.192831 10Of course, when running mo_phylum("Firmicutes") the function has zero knowledge about the actual microorganism, namely S. aureus. But since the result would be "Firmicutes" too, there is no point in calculating the result. And because this package ‘knows’ all phyla of all known microorganisms (according to ITIS), it can just return the initial value immediately.
Results in other languages
When the system language is non-English and supported by this AMR package, some functions take a little while longer:
mo_fullname("CoNS", language = "en") # or just mo_fullname("CoNS") on an English system
# "Coagulase Negative Staphylococcus (CoNS)"
mo_fullname("CoNS", language = "fr") # or just mo_fullname("CoNS") on a French system
# "Staphylococcus à coagulase négative (CoNS)"
microbenchmark(en = mo_fullname("CoNS", language = "en"),
de = mo_fullname("CoNS", language = "de"),
nl = mo_fullname("CoNS", language = "nl"),
es = mo_fullname("CoNS", language = "es"),
it = mo_fullname("CoNS", language = "it"),
fr = mo_fullname("CoNS", language = "fr"),
pt = mo_fullname("CoNS", language = "pt"),
times = 10,
unit = "ms")
# Unit: milliseconds
# expr min lq mean median uq max neval
# en 6.093583 6.51724 6.555105 6.562986 6.630663 6.99698 100
# de 13.934874 14.35137 16.891587 14.462210 14.764658 43.63956 100
# nl 13.900092 14.34729 15.943268 14.424565 14.581535 43.76283 100
# es 13.833813 14.34596 14.574783 14.439757 14.653994 17.49168 100
# it 13.811883 14.36621 15.179060 14.453515 14.812359 43.64284 100
# fr 13.798683 14.37019 16.344731 14.468775 14.697610 48.62923 100
# pt 13.789674 14.36244 15.706321 14.443772 14.679905 44.76701 100Currently supported are German, Dutch, Spanish, Italian, French and Portuguese.