7.4 KiB
7.4 KiB
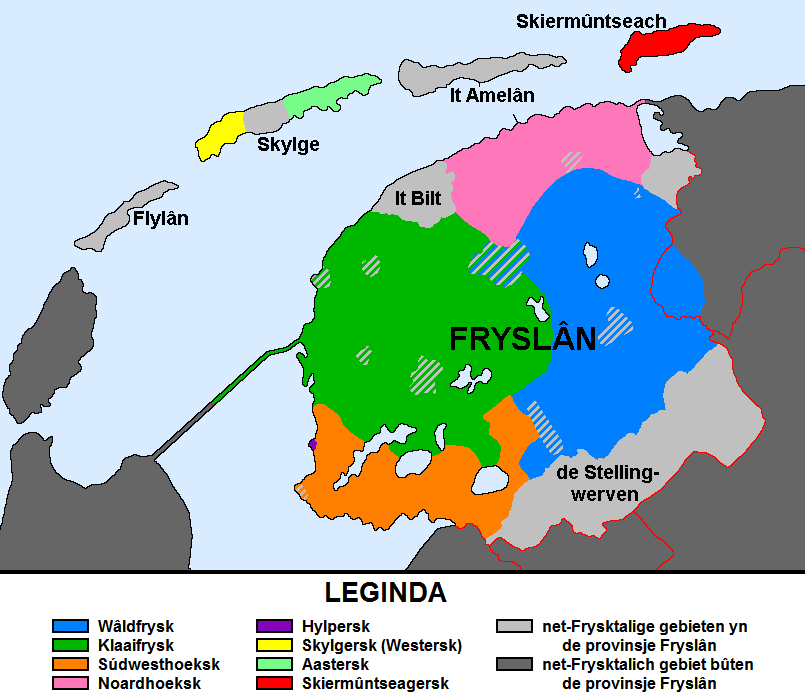
Group recordings in 4 Frysian dialect regions¶
- Klaaifrysk
- Waldfrysk
- Sudwesthoeksk
- Noardhoeksk
First run Dialect Regions from image.ipynb.
In [1]:
from math import floor import json import pandas import MySQLdb from collections import Counter from math import sqrt import numpy as np from shapely.geometry import shape, Point from vincenty import vincenty from jupyter_progressbar import ProgressBar db = MySQLdb.connect(user='root', passwd='Nmmxhjgt1@', db='stimmen', charset='utf8')
Input¶
Load the geojson with the dialect region and create shapely shapes.
In [2]:
with open('dialect_regions.geojson', 'r') as f: geojson = json.load(f) dialect_regions = [region['properties']['dialect'] for region in geojson['features']]
In [3]:
shapes = { feature['properties']['dialect']: shape(feature['geometry']) for feature in geojson['features'] } def regions_for(coordinate): regions = { region_name for region_name, shape in shapes.items() if shape.contains(Point(*coordinate)) } return regions def distance_to_shape(shape, longitude, latitude): ext = shape.exterior p = ext.interpolate(ext.project(Point(longitude, latitude))) return vincenty((latitude, longitude), (p.y, p.x))
Query and process¶
Query all picture game and free speech recordings and assign the dialect region.
In [4]:
def dialect_regions_and_distance(data): return[ { 'dialects': [ { 'dialect': dialect, 'boundary_distance': distance_to_shape(shapes[dialect], longitude, latitude), } for dialect in regions_for((longitude, latitude)) ], 'filename': filename, } for filename, (latitude, longitude) in ProgressBar( data[['latitude', 'longitude']].iterrows(), size=len(data) ) ]
In [5]:
picture_games = pandas.read_sql(''' SELECT language.name as language, item.name as picture, survey.user_lat as latitude, survey.user_lng as longitude, survey.area_name as area, survey.country_name as country, result.recording as filename, result.submitted_at as date FROM core_surveyresult as survey INNER JOIN core_picturegameresult as result ON survey.id = result.survey_result_id INNER JOIN core_language as language ON language.id = result.language_id INNER JOIN core_picturegameitem as item ON result.picture_game_item_id = item.id ''', db) picture_games.set_index('filename', inplace=True)
In [6]:
dialect_region_per_picture_game = dialect_regions_and_distance(picture_games)
VBox(children=(HBox(children=(FloatProgress(value=0.0, max=1.0), HTML(value='<b>0</b>s passed', placeholder='0…
In [7]:
df = pandas.DataFrame([ [r['filename'], r['dialects'][0]['dialect'], r['dialects'][0]['boundary_distance']] for r in dialect_region_per_picture_game if len(r['dialects']) == 1 ], columns = ['filename', 'dialect', 'boundary_distance']) df.to_excel('../data/picture_game_recordings_by_dialect.xlsx') df.to_csv('../data/picture_game_recordings_by_dialect.csv')
In [8]:
free_speech_games = pandas.read_sql(''' SELECT language.name as language, survey.user_lat as latitude, survey.user_lng as longitude, survey.area_name as area, survey.country_name as country, result.recording as filename, result.submitted_at as date FROM core_surveyresult as survey INNER JOIN core_freespeechresult as result ON survey.id = result.survey_result_id INNER JOIN core_language as language ON language.id = result.language_id ''', db) free_speech_games.set_index('filename', inplace=True)
In [9]:
dialect_region_per_free_speech = dialect_regions_and_distance(free_speech_games)
VBox(children=(HBox(children=(FloatProgress(value=0.0, max=1.0), HTML(value='<b>0</b>s passed', placeholder='0…
In [10]:
df = pandas.DataFrame([ [r['filename'], r['dialects'][0]['dialect'], r['dialects'][0]['boundary_distance']] for r in dialect_region_per_free_speech if len(r['dialects']) == 1 ], columns = ['filename', 'dialect', 'boundary_distance']) df.to_excel('../data/free_speech_recordings_by_dialect.xlsx') df.to_csv('../data/free_speech_recordings_by_dialect.csv')